
Hands-On with Claude Opus 4.6 vs Gemini 3 Pro vs GPT-5.2
I tested Anthropic's newest Claude Opus 4.6 against Gemini 3 Pro and GPT-5.2 in a real 3-prompt product prototype. Here's what actually worked and where each model excels.
Breaking News
Claude Opus 4.6 just dropped on February 5, 2026, and I immediately tested it inside Claude Code, VS Code, and built a product prototype from scratch to compare it against the top frontier models.
The AI landscape is evolving at a blistering pace. Within months, we've seen Anthropic release Claude Opus 4.6, Google launch Gemini 3 Pro, and OpenAI push out GPT-5.2. Each claims to be the best. But which one actually delivers for engineering workflows?
I put them to the test with a real use case: building a product prototype from scratch using just 3 prompts.
The TL;DR
Before we dive deep, here's the quick summary:
| Capability | Winner | Key Stat |
|---|---|---|
| Agentic Coding | Claude Opus 4.6 | 65.4% on Terminal-Bench 2.0 |
| Knowledge Work | Claude Opus 4.6 | 1606 Elo on GDPval-AA |
| Reasoning (with tools) | Claude Opus 4.6 | 53.1% on Humanity's Last Exam |
| Multimodal | Gemini 3 Pro | 81% on MMMU-Pro |
| Long Context | Claude Opus 4.6 | 1M tokens (beta) |
| Ecosystem Integration | GPT-5.2 | Mature tooling |
What Makes Opus 4.6 Different?
Claude Opus 4.6 isn't just an incremental update—it's a focused upgrade for long-running knowledge work, agentic coding workflows, and enterprise productivity tasks.
1 Million Token Context Window (Beta)
Opus 4.6 can now process up to 1 million tokens in beta. This means you can feed it entire codebases, book-length documents, or complex multi-file engineering tasks without losing context. It's designed to mitigate "context rot" that plagues other models on long inputs.
Agent Teams in Claude Code
This is a game-changer. Multiple AI agents can now collaborate autonomously on coding projects. You can break multi-step engineering tasks into subagents that work in parallel—like having a junior dev team that never sleeps.
Excel & PowerPoint Research Preview
Anthropic highlights significant improvements in spreadsheet automation and document generation. Financial modeling and presentation creation are now first-class citizens.
The Benchmarks Don't Lie
Let's look at how these models compare across key areas. I'm using the official benchmarks from Anthropic, Google, and OpenAI's announcements.
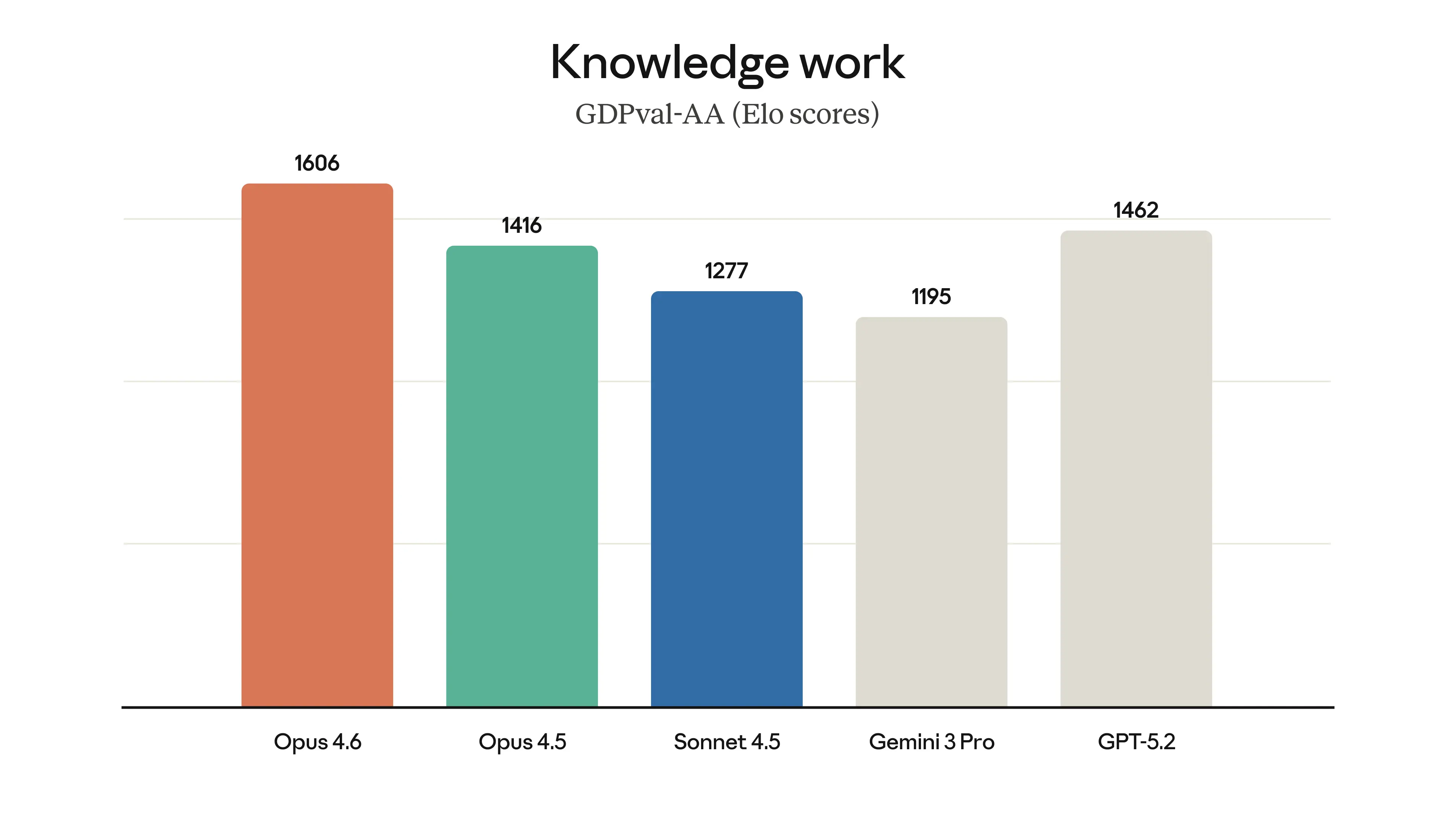
Opus 4.6 is state-of-the-art on real-world work tasks across several professional domains.
Key Benchmark Highlights
Claude Opus 4.6:
- 68.8% on ARC AGI 2 (novel problem-solving)—outperforming GPT-5.2 Pro (54.2%) and Gemini 3 Pro (45.1%)
- 90.2% on BigLaw Bench for legal reasoning
- 1606 Elo on GDPval-AA, beating GPT-5.2 by ~144 Elo points
Gemini 3 Pro:
- 81% on MMMU-Pro for multimodal understanding
- 91.9% on GPQA Diamond for PhD-level reasoning
- 1501 Elo on LMArena Leaderboard
GPT-5.2:
- 100% on AIME 2025 for mathematics
- 93.2% on GPQA Diamond (highest for graduate-level reasoning)
- Perfect accuracy up to 256k tokens on MRCR v2
The Full Comparison Table
Here's the comprehensive benchmark comparison:
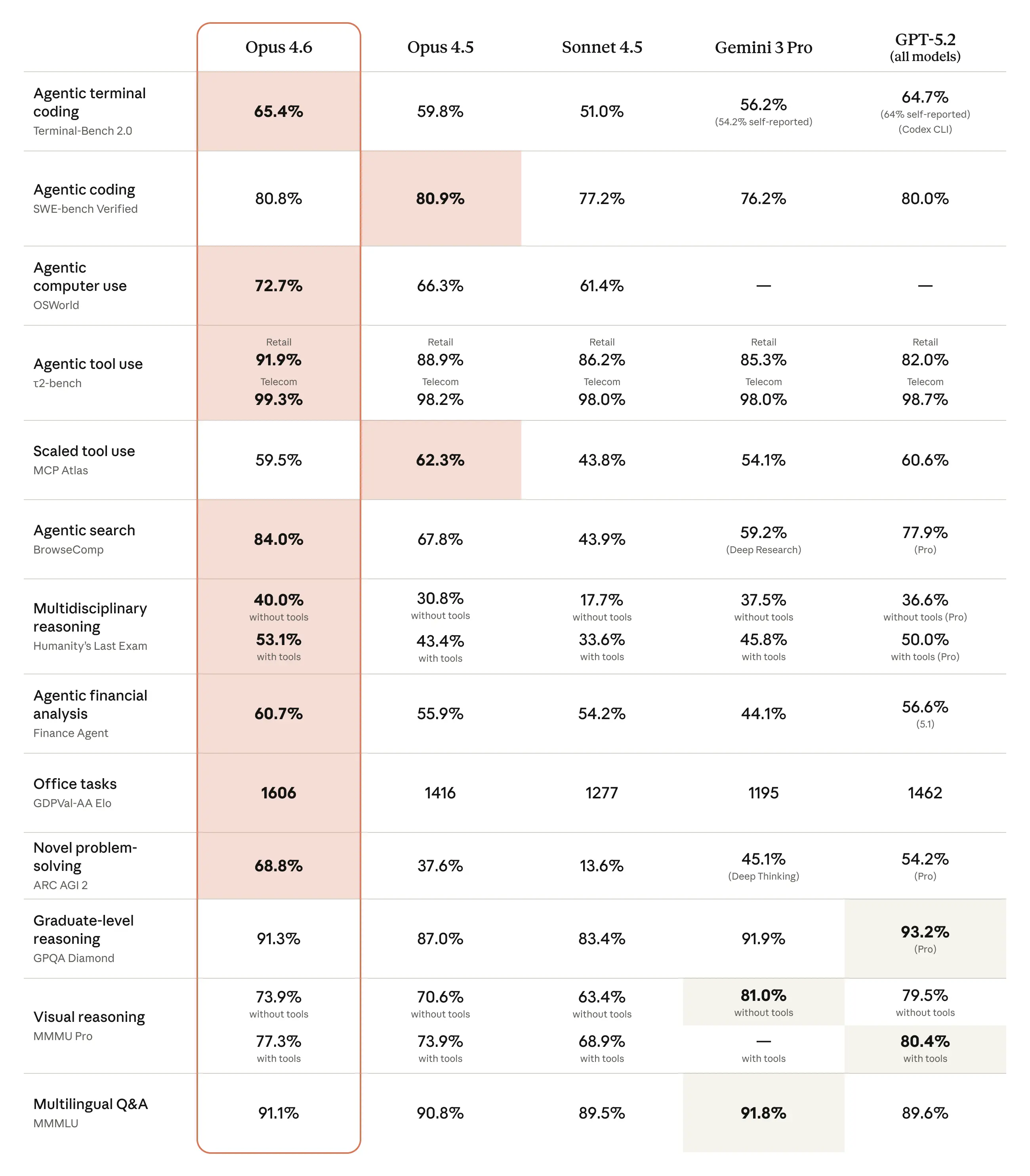
Complete benchmark comparison between Claude Opus 4.6, Opus 4.5, Sonnet 4.5, Gemini 3 Pro, and GPT-5.2
My Real-World Test: 3-Prompt Product Prototype
Theory is nice, but I wanted to see how these models perform in a real engineering workflow. I built a minimal product prototype—a simple SaaS dashboard—using exactly 3 prompts with each model.
The Prompt
"Design a minimal SaaS dashboard for tracking personal finance. Output a structured PRD with features, tech stack, and initial data model."
Opus 4.6
Produced the most comprehensive PRD. Included Excel automation hooks, suggested integrations with banking APIs, and proposed a PowerPoint-export feature. Felt like a senior PM output.
Gemini 3 Pro
Strong decision rationale and multimodal ideas (suggested chart visualizations upfront). Nuanced reasoning, but less actionable for immediate coding.
GPT-5.2
Focused heavily on agentic steps and CI/CD. Good for DevOps-minded projects, but the PRD was more tactical than strategic.
Verdict
For my long-context, multi-file developer workflow, Opus 4.6 outperformed the competition. It required the fewest manual interventions to get production-ready code.
Using Opus 4.6 Inside Claude Code & VS Code
I tested Opus 4.6 through Claude Code CLI and the Continue extension in VS Code. Here's what I observed:
Claude Code CLI
The new agent teams feature is incredible. I could spin up sub-agents for:
- Backend API scaffolding
- Frontend component generation
- Test writing
All running in parallel. The main agent coordinated results and merged them intelligently. For complex refactoring tasks across multiple files, this is a productivity multiplier.
VS Code Integration
Using Opus 4.6 via the API in VS Code extensions, the model maintained context across my entire project. I could ask questions about files I hadn't opened in hours, and it remembered the architecture decisions we'd made together.
The 1 million token context window means I can feed it my entire monorepo and ask complex cross-cutting questions without summarization hacks.
When to Pick Each Model
Based on my testing and the benchmarks, here's my recommendation:
Choose Claude Opus 4.6 If:
- You work with long documents (contracts, research papers, full codebases)
- You need financial modeling or Excel automation
- You want agentic coding workflows with multiple parallel tasks
- You prioritize minimal follow-ups to get production-ready output
- You work in legal, finance, or enterprise contexts
Choose Gemini 3 Pro If:
- You need multimodal understanding (images, video, audio + text)
- You work on research tasks requiring deep reasoning
- Speed and cost-effectiveness are priorities
- You're building creative applications that mix media types
Choose GPT-5.2 If:
- You need the broadest ecosystem integrations (Microsoft/Office, Copilot)
- You work with vision-enabled agentic pipelines
- You need tool-calling orchestration across many services
- Mathematical reasoning is core to your workflow
The Bottom Line
Claude Opus 4.6 represents a meaningful leap for professional knowledge work and agentic coding. It's not just marginally better—it fundamentally changes how you can structure AI-assisted development workflows.
The agent teams feature in Claude Code is worth the upgrade alone. Combined with the 1M token context and improvements in finance/legal benchmarks, Opus 4.6 is positioned as the go-to model for serious engineering work.
Gemini 3 Pro remains unmatched for multimodal synthesis, and GPT-5.2 offers the most mature ecosystem. But for pure coding productivity? Opus 4.6 takes the crown.
What's your experience with these models? Drop a comment or clap if this breakdown helped you decide which model to try next!

Author Parth Sharma
Full-Stack Developer, Freelancer, & Founder. Obsessed with crafting pixel-perfect, high-performance web experiences that feel alive.
Typography as Interface: Why Inter and Outfit Rule the Web
Next Article →I Replaced Google with AI for 7 Days. Here's What Broke.
Discussion1
Join the conversation
Sign in to leave a comment, like, or reply.
🔥🔥